Latent Semantic Indexing
Latent semantic indexing (LSI) provides the ability to correlate semantically related terms that could be latent in the set of documents. Latent semantic analysis allows us to see semantics in the set of documents and how we can extract meaning of the text in the documents.This is used to get a response to queries that return more “meaningful” results and not just a keyword search.
Excerpt from Wikipedia: Latent Semantic Indexing Wiki
“A key feature of LSI is its ability to extract the conceptual content of a body of text by establishing associations between those terms that occur in similar contexts….. The method, also called latent semantic analysis (LSA), uncovers the underlying latent semantic structure in the usage of words in a body of text and how it can be used to extract the meaning of the text in response to user queries, commonly referred to as concept searches. Queries, or concept searches, against a set of documents that have undergone LSI will return results that are conceptually similar in meaning to the search criteria even if the results don’t share a specific word or words with the search criteria”
Source code:
This is a very old code-base that was created in 2008 for my PhD admissions and made public much later. Also, this is not a very well organized code - and perhaps not very efficient either. I encourage people to use this only for reference and implement efficient code of your own. If you do, and willing to share it, please send me the link to your page (or the code) and I will update my page to include your link.
Understanding LSI
This has been done before by Dr. E. Garciaand in explained in good enough detail - I won’t be doing justice to this topic if I explained it again.
If needed, read through the pre-requisites mentioned in the tutorial above.
In this article, I will be explaining the steps followed in the source-code in two parts.
- Part 1 - What the code does. You are currently reading it.
- Part 2 - Indexing
- Part 3 - Search and results
Below is the demo implementation in C#.NET.
Examples from sample collection of documents
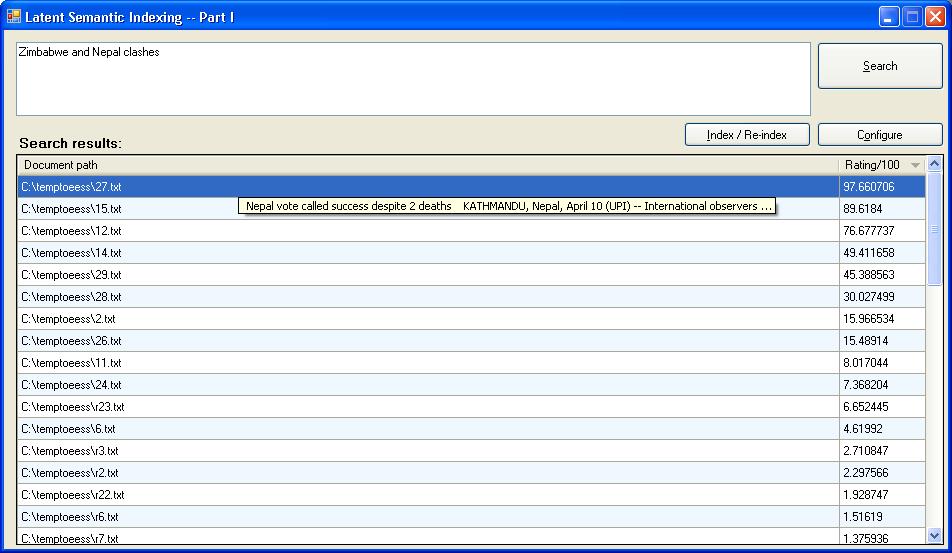
Simple search query w.r.t. contents in the sample. Show the matching documents. Rank approximation: 35% of collection
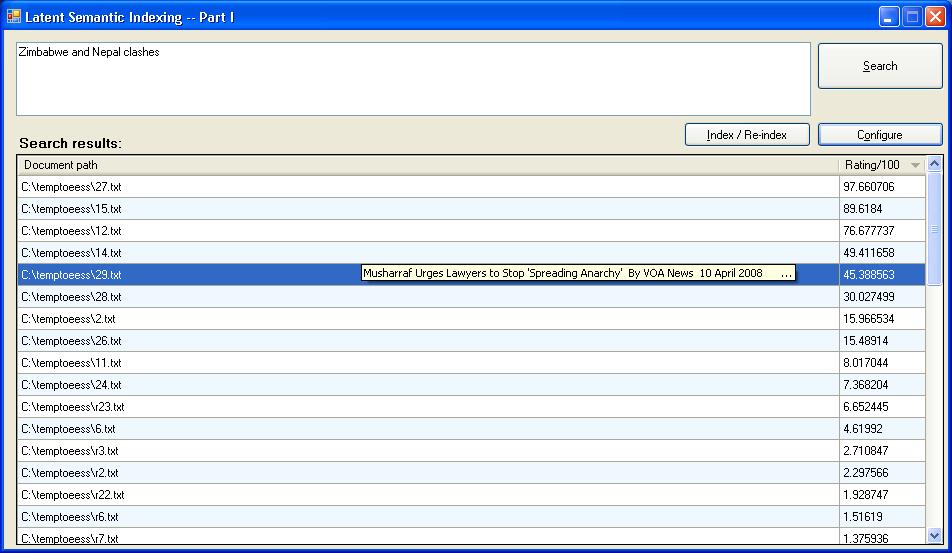 The same query, but see the document in highlighted result. The document mentions word “fighting” which is synonymous to “clash”. (Of course, the collection must have enough content to be able to establish synonymy). Rank approximation: 35% of collection
The same query, but see the document in highlighted result. The document mentions word “fighting” which is synonymous to “clash”. (Of course, the collection must have enough content to be able to establish synonymy). Rank approximation: 35% of collection
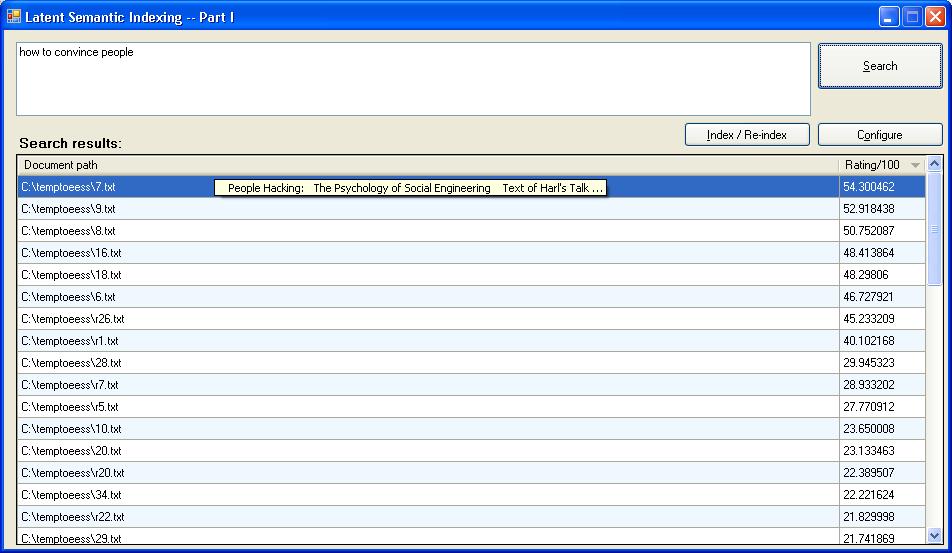
Another random query that just occurred to me. The word “people” is present in the documents. The word “convince” does not occur in the highlighted document. But, interestingly, it ranks documents related to “social engineering”.Rank approximation: 35% of collection
Part 2: - Creating Index …. Continue reading >
References:
Updated