LLM-Powered Agent in Python - Building Agents Part 2
Build an LLM-powered agent in Python: use GPT-5 to turn natural language into structured data, then apply simple rules for smart meal suggestions.

Why We Need Something Smarter
In Part 1, we built a Simple Decision-Making Agent. It worked like this:
- You gave it structured input like a list of ingredients, a number for hunger (1–5), and minutes available.
- It followed simple rules to suggest a meal.
Example input:
agent.perceive(["bread", "cheese", "eggs"], hunger=5, time=10)
Example output:
👩🍳 Suggested Meal: Cheese Omelette Sandwich
We build on top of "Part 1 - Simple Decision-Making Agent", and this gets a bit more complex. Please make sure you understand the first part.
Problem With Part 1
What happens if a user types:
"I’m kinda hungry and I have leftover rice and two eggs, but I’m in a bit of a rush."
Our first agent would break because:
- It only understood numbers, not “kinda hungry”.
- It didn’t know how long “a bit of a rush” is.
- It couldn’t handle natural language at all.
Enter the LLM (Large Language Model)
This is where LLMs like GPT-5 shine.
They can:
- Understand natural language (messy, human-like input).
- Extract structured data from text.
- Translate fuzzy ideas (“in a rush”) into valid numbers (say, 10 minutes).
So the LLM becomes the “ears and brain” of our agent, while our old rule-based logic remains the “decision-making core.”
How the LLM-Powered Agent Works
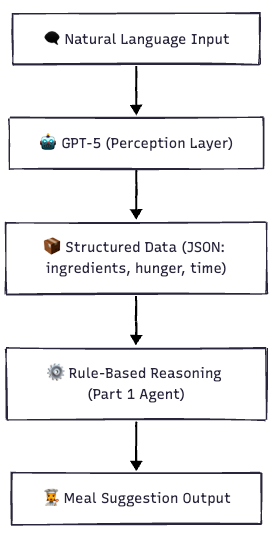
⚙️ Environment Setup
1. Create a fresh virtual environment
Using venv:
python3 -m venv ~/.venvs/agents
source ~/.venvs/agents/bin/activate
Using conda (avoid base env):
conda create -n agents python=3.11 -y
conda activate agents
2. Install the latest OpenAI SDK
pip install -U pip setuptools wheel
pip install -U openai python-dotenv
3. Verify the version
python -c "import importlib.metadata as m; print('openai==', m.version('openai'))"
You should see openai >= 1.14.0.
If you see an older version (like 1.10.x), you’re using a pinned environment - switch to the venv/conda env above.
4. Set your API key
Create a .env file:
OPENAI_API_KEY="sk-..." # put your key here
NOTE: We use OpenAI’s GPT-5 here, but the same setup works with other services or LLMs, including locally hosted ones. This example doesn’t require GPT-5-level intelligence.
Writing the LLM-Powered Agent in Python
Step 1: JSON Schema for Structured Outputs
MEAL_SCHEMA = {
"type": "object",
"properties": {
"ingredients": {"type": "array", "items": {"type": "string"}},
"hunger": {"type": "integer", "minimum": 1, "maximum": 5},
"time": {"type": "integer", "minimum": 0}
},
"required": ["ingredients", "hunger", "time"],
"additionalProperties": False
}
Step 2: GPT-5 Parsing Function
import json
from openai import OpenAI
from dotenv import load_dotenv
# Load API key from .env
load_dotenv()
client = OpenAI()
def parse_user_input_with_llm(user_input: str, model: str = "gpt-5") -> dict:
resp = client.chat.completions.create(
model=model, # use gpt-4o if gpt-5 isn’t available
messages=[
{"role": "system", "content":
"Extract 3 fields and reply ONLY with JSON matching the schema: "
"ingredients (list[str]), hunger (1-5), time (minutes). "
"If user is vague (e.g., 'in a rush'), infer a reasonable time."},
{"role": "user", "content": user_input}
],
response_format={
"type": "json_schema",
"json_schema": {"name": "meal_inputs", "schema": MEAL_SCHEMA}
}
)
return json.loads(resp.choices[0].message.content)
Step 3: Use It With Our Old MealAgent
agent = MealAgent() # from Part 1
user_input = "I have eggs and rice. I'm very hungry but in a rush."
parsed = parse_user_input_with_llm(user_input)
agent.perceive(parsed['ingredients'], parsed['hunger'], parsed['time'])
agent.act()
For the code on MealAgent look at Part 1 - Simple Decision-Making Agent
Example Run
Input:
"I have eggs and rice. I'm very hungry but in a rush."
Output:
👩🍳 Suggested Meal: Egg Fried Rice
But, there's a problem.
Input:
"I have 2 eggs and leftover rice. I'm very hungry but in a rush."
Output:
👩🍳 Suggested Meal: Sorry, no suitable meal.
As you can see, it was unable to infer the parameters correctly. Upon examining the parsed input, we notice that it contains extra words in the ingredients.
Parsed Input:
{'ingredients': ['2 eggs', 'leftover rice'], 'hunger': 5, 'time': 10}Now we could normalize the inputs, but that defeats the whole point of using AI. You shouldn’t have to “manually babysit” the model with post-processing if the entire point of this Part-2 agent is that the LLM itself does the messy cleanup. What you want is to shift the burden onto the LLM perception layer.
How to fix it inside the LLM
Update your system message so the model canonicalizes ingredients:
{"role": "system", "content": """
Extract 3 fields and reply ONLY with JSON matching the schema:
- ingredients (list[str]): Canonical ingredient names only, pluralized where natural.
• Remove numbers (e.g., "2 eggs" → "eggs")
• Remove adjectives (e.g., "leftover rice" → "rice", "boiled egg" → "eggs")
• Use simple grocery-style labels that match common recipes.
- hunger (1–5)
- time (minutes)
If user is vague (e.g., "in a rush"), infer a reasonable time.
"""}
This maintains the “AI-ness”: your rule-based MealAgent receives clean tokens. For example, the input will result in a correctly parsed input.
"I have 2 eggs and leftover rice. I'm very hungry but in a rush."
Parsed input is
{'ingredients': ['eggs', 'rice'], 'hunger': 5, 'time': 10}However, the old, simple decision-making MealAgent will not return a recipe because it is a strict, rule-based system, and it has the "Egg Fried Rice" recipe that takes 15 minutes. And the LLM inferred "in a rush" as "10 minutes"
NOTE: In the first run the same LLM inferred “in a rush” for more time when it had a fewer words. There will be inconsistencies near edges. Be aware of that.
We have a few solutions here:
- Relax the recipe time to use shortfalls.
- Have more recipes
- Make the agent forgiving, allow for tiny shortfalls in the
MealAgent
However, that is not a problem we will solve here. For now, we can proceed with a simpler change to the system role content.
"""...
If user is vague (e.g., "in a rush"), infer a reasonable time.
If not in a rush, use a default time of 30 minutes."
"""So when the user is "not in a rush", we can get an output like
User Input: "I have 2 eggs and leftover rice. I'm very hungry"
Parsed Input: {'ingredients': ['eggs', 'rice'], 'hunger': 5, 'time': 30}
👩🍳 Suggested Meal: Egg Fried Rice
What is Structured Output?
Usually, when you ask GPT to output JSON, it might sneak in explanations, extra text, or malformed JSON.
Structured Outputs fix this:
- You give GPT a JSON schema (the exact structure you want)
- GPT is forced to output exactly that format
- Safer than parsing raw text and avoids errors
Think of it like giving GPT a form template.It must fill in the blanks, but cannot change the shape.
Why This Is Better
- Users can type naturally.
- Fuzzy inputs are interpreted (e.g. “rush” = 10 minutes).
- Output is always valid JSON.
- Still uses the simple, explainable rules from Part 1.
Coming Up Next
But what if the input is too vague?
- “I’m kinda hungry.” → Is that hunger 3 or 4?
- “Not much time” → 5 minutes or 15?
In the next part, we’ll teach the agent to ask clarifying questions instead of guessing. This makes it even more human-like.
Stay tuned!

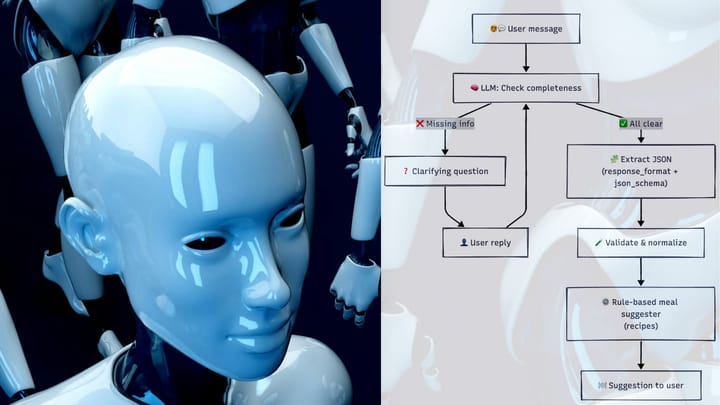
Comments ()