Latent Semantic Indexing - part 3 - Search
March 23, 2008 • 2 min read
This is a continuation in the series of LSI (Latent Semantic Indexing) implementation. In this post, we will walk through the implementation of searching an index based on user's query.
In the earlier post, we saw how to create an index from the list of documents. In this post, we will see how to search the index created earlier. This is only a walkthrough of the code - you should be able to map these steps to the code based on the inline comments.
After the user types in a query and clicks Search, the following is performed
Step 1: Fetch the data from the Index
Fetch the data from the Index that we stored. In this case, it is:
- Documents list
- Word list
- (S(k)(inverse))
- U(k)
- WTDM (weighted-term-document-matrix)
Step 2: Fetch the query text
Fetch the query text and filter stop words and apply stemming on this vector. Stemming is done using the same mechanism that we used above.
Step 3: Create a vector
Create a vector using words list - called [q(transpose) - qT].
This is used to create the query vector
Step 4: Normalize qT (simple normalization).
Normalize qT using simple normalization.
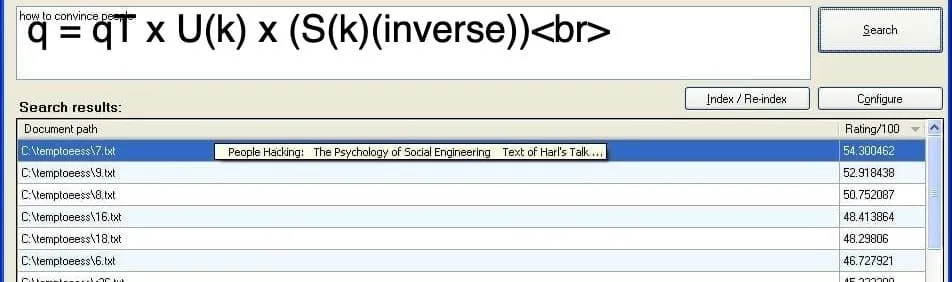
Step 5: Compute the query-vector
Compute the query-vector as shown below:
q = qT x U(k) x (S(k)(inverse))Step 6: Create a document vector
Now that we have the query vector, create a document vector for comparison with the query vector
This document vector may be created while indexing too
- For each document:
-
- Create a vector dT - transpose of document
Compute document vector
d = dT x U(k) x (S(k)(inverse))Step 7: Compute similarities
Finally, we compute the similarities in query and document.
- Initialize results - list of
similarityArray - For each document:
-
- Fetch the document vector
d
- Fetch the document vector
Compute cosine similarity between query vector q and vector d
similarityArray[documentID] = similarity(from above)We then display the similarityArray in a descending order.
Not covering the UI part here. I think it is pretty simple to understand the UI created for this
I hope you found this series useful. If it was helpful to you, please share!